
概要
- 列の編集はdplyr::mutate()関数がお勧め
- 列の内容変更や新規追加がmutate()ひとつで可能
- 一気に複数列を上書きする発展的な関数もある
イメージ
今回紹介する「列の編集」という操作のイメージは次の図のようなものです。
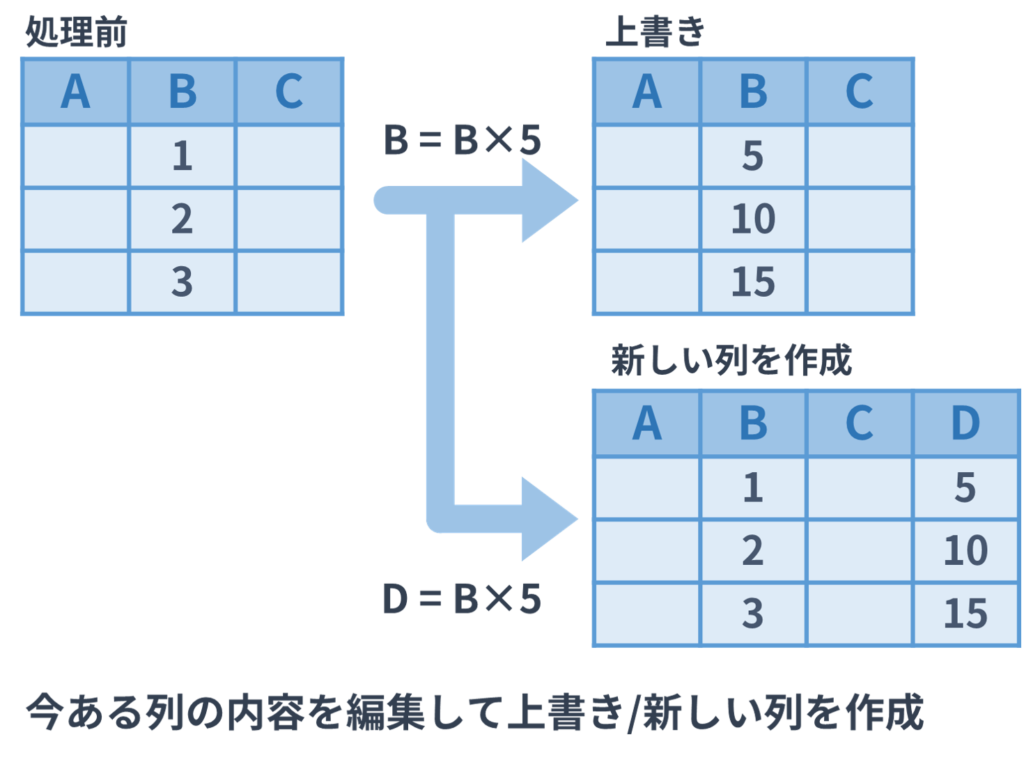
dplyr::mutate()
列の編集にお勧めの関数はdplyrパッケージのmutate()関数です。この関数はすでにある列の内容を編集して上書きしたり、新しい列を作ったりする関数です。読み込んだデータの内容を編集する場合には便利な関数です。
基本的な使い方
mutate()関数の基本的な使い方は以下の通りです。
library(dplyr) mutate(データフレーム, 列名 = 列の中身)
基本的な引数は以下の通りです。
- データフレーム:編集したい列があるデータフレーム
- 列名 = 列の中身:編集したい列の名前と編集内容のペア
列の追加
列を追加する時はmutate()関数で指定する列名を今ある列名でないものに指定します。
例えば、iris データの Sepal.Length を Sepal.Width で割ったものを計算して、新しく Sepal.Rate という列を追加する場合のコードは以下のようになります。
library(dplyr) mutate(iris, Sepal.Rate = Sepal.Length / Sepal.Width) # Sepal.Length Sepal.Width Petal.Length Petal.Width Species Sepal.Rate #> 1 5.1 3.5 1.4 0.2 setosa 1.457143 #> 2 4.9 3.0 1.4 0.2 setosa 1.633333 #> 3 4.7 3.2 1.3 0.2 setosa 1.468750 #> 4 4.6 3.1 1.5 0.2 setosa 1.483871 #> 5 5.0 3.6 1.4 0.2 setosa 1.388889 #> 6 5.4 3.9 1.7 0.4 setosa 1.384615 #> 7 4.6 3.4 1.4 0.3 setosa 1.352941 #> 8 5.0 3.4 1.5 0.2 setosa 1.470588 #> 9 4.4 2.9 1.4 0.2 setosa 1.517241 #> 10 4.9 3.1 1.5 0.1 setosa 1.580645
見てわかるとおり出力結果に「Sepal.Rate」という新しい列が加えられており、その値も「Sepal.Length / Sepal.Width」の計算結果となっています。
列の上書き
列を上書きする時は指定する列名を上書きしたい列の列名にします。
例えば iris データの Species 列を編集して 中身を最初の2文字だけに省略する場合のコードは以下のようになります。
library(tidyverse) mutate(iris, Species = str_sub(Species, 1, 2)) # stringr::str_sub()で文字を部分抽出している # Sepal.Length Sepal.Width Petal.Length Petal.Width Species #> 1 5.1 3.5 1.4 0.2 se #> 2 4.9 3.0 1.4 0.2 se #> 3 4.7 3.2 1.3 0.2 se #> 4 4.6 3.1 1.5 0.2 se #> 5 5.0 3.6 1.4 0.2 se #> 6 5.4 3.9 1.7 0.4 se #> 7 4.6 3.4 1.4 0.3 se #> 8 5.0 3.4 1.5 0.2 se #> 9 4.4 2.9 1.4 0.2 se #> 10 4.9 3.1 1.5 0.1 se
出力結果を見てみると、「Species」列の中身が簡略化されて先頭の2文字だけになっています。
複数列を一気に上書き
dplyr::mutate()関数の発展的な関数として複数の列を一気に上書きする関数があります。どのように複数列を指定するのかが異なるのでそれぞれ紹介します。
列名で複数列を指定
列名で複数列を指定して一気に上書きするときは dplyr::mutate_at()関数がお勧めです。irisデータの中で列名が「Sepal」で始まる列をその列の値のランキングに書き換えるコードは以下のコードです。
library(dplyr)
mutate_at(.tbl = iris,
.vars = vars(starts_with("Sepal")), # 列の選択法を指定(列名が「Sepal」で始まる列を指定)
.funs = dense_rank) # 対象列の値を小さい順に並べたときの順番(ランキング)を計算
#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 1 9 15 1.4 0.2 setosa
#> 2 7 10 1.4 0.2 setosa
#> 3 5 12 1.3 0.2 setosa
#> 4 4 11 1.5 0.2 setosa
#> 5 8 16 1.4 0.2 setosa
出力結果を見ると「Sepal」で始まる列(Sepal.LengthとSepal.Width)の値がランキングに置き換えられています。
mutate_at()関数の主な引数は以下の通りです。
- .tbl:処理を行う対象となるデータフレーム
- .vars:対象となる列名の指定(列名や列番号などを使って指定)
- .funs:対象の列に適応する関数
ポイントはmutate_at()関数では列の指定を .vars = で指定する点で、この引数に対しては列名の文字列ベクトルや列番号の数値ベクトルも指定できますし、さらには vars()関数内で tidy selectionsも使うことができます。
列の内容で複数列を指定
列の内容で複数列を指定して一気に上書きする時はdplyr::mutate_if()関数がお勧めです。irisデータの数値型の列をランキングに書き換える場合のコードは以下の通りです。
library(dplyr)
mutate_if(.tbl = iris,
.predicate = is.numeric,
.funs = dense_rank)
#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 1 9 15 5 2 setosa
#> 2 7 10 5 2 setosa
#> 3 5 12 4 2 setosa
#> 4 4 11 6 2 setosa
#> 5 8 16 5 2 setosa
Species列以外の列が測定値ではなくランキングに置き換えられているのが確認できます。
mutate_if()関数の主な引数は以下の通りです。
- .tbl:処理を行う対象となるデータフレーム
- .predicate:対象となる列名の指定(関数を使って列を指定する)
- .funs:対象の列に適応する関数
ポイントはmutate_if()では列の指定を関数を使っておこなうことです。無名関数などをうまく使えば様々な関数を駆使して列の指定をすることができます。
全ての列を指定
全ての列を一気に上書きする時は dplyr::mutate_all()関数が使えます。
library(dplyr)
mutate_all(.tbl = iris,
.funs = dense_rank)
#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 1 9 15 5 2 1
#> 2 7 10 5 2 1
#> 3 5 12 4 2 1
#> 4 4 11 6 2 1
#> 5 8 16 5 2 1
結果をみてみると全ての列がランキングの値に置き換えられていることが確認できます。
mutate_all()関数の主な引数は以下の通りです。
- .tbl:処理を行う対象となるデータフレーム
- .funs:対象の列に適応する関数
mutate_all()関数では対象の列を選ぶ必要が無いので単純にどのデータフレームを対象にどのような関数を適応すればよいかを指定するだけで大丈夫です。