
概要
- ヒストグラムはgeom_histogram()関数を使う
- ヒストグラムでデータの分布を確認/比較
イメージ
ヒストグラムを作るときはggplot()で外枠を作成しgeom_histogram()でヒストグラム自身を作成します。
geom_histogram()でヒストグラムを作るときのイメージは下の図の通りです
ヒストグラムはggplot() + geom_histgram()で作成する。
使い方
基本的なヒストグラムの作り方は下の通りです。
library(ggplot2) # まずはggplotを使うためにライブラリーを呼び出す ggplot(data = data, mapping = aes(x = x)) + # 使うデータやx軸として使う項目の設定 geom_histogram() # ヒストグラムを描画することを指示
「data = 」で作図に使うデータフレームを指定し、「mapping = aes(x =)」でX軸に使用する列(ヒストグラムで分布を確認したい項目)を指定します。
またヒストグラムを作る際に指定できる基本的な項目は以下の通りです。
aesの中で指定するもの
- x:X軸に使う項目
- y:Y軸に使う項目
- fill:棒の塗りつぶし色
- color:棒の枠線の色
- linetype:枠線の線の種類(実線や点線など)
aesの外で指定できるもの
- binwidth:階級幅(棒の幅)
- bins:階級数(棒の数)
- position:複数データの位置関係(積み重ねたり、独立させたりを設定)
- alpha:透過性(塗りつぶしや枠の色の透過性)
- color:棒の枠線の色(aesの外で設定すると全ての色を同じに指定可能)
- fill:棒の塗りつぶし色(外で設定すると全ての色を同じに指定可能)
- size:棒の枠線の太さ
- data:作図に使用するデータ
具体例
ここからは少し具体例を挙げていきます。今回はRStudioに最初から入っている irisデータを使って色々なヒストグラムを作成してみます。
基本のヒストグラム
まず初めに基本のヒストグラムの作り方を紹介したいと思います。今回はirisデータの「Petal.Length」列に関してヒストグラムを作成するコードを紹介します。
library(ggplot2) ggplot(data = iris, aes(x = Petal.Length)) + geom_histogram()
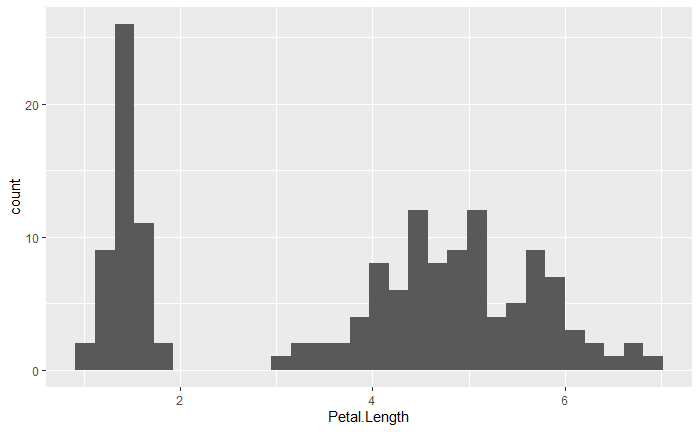
基本のヒストグラムを作るに時は使うデータセット(data = iris)とx軸に使う列の列名(aes(x = Petal.Length))を指定するだけで大丈夫です。
基本のヒストグラムは「 使うデータセット」と「x軸」を指定すればOK。
ただ、最小限のことを指定するだけではあまりきれいな見た目とは言えないかと思います。
また、作成したヒストグラムを見てみると、ピークが少なくとも2か所にあることが確認できるので、異なる複数の集団が混ざっていることが予想されます。次の具体例では、これについてさらに深掘りします。
複数のデータを重ねる
次に複数のデータを色を塗り分けて重ねる場合を紹介します。データの中に複数の種類のデータが含まれている場合は色を塗り分けて、それぞれ別に集計することができます。
今回は先ほどと同じくirisデータの「Petal.Length」列に関して、今度は「Species」ごとに色を塗り分けて作図する例を紹介します。
library(ggplot2) ggplot(data = iris, aes(x = Petal.Length, fill = Species, color = Species)) + # fillとcolorをSpeciesごとに変える geom_histogram(position = "identity", alpha = .6) # position = "identity"でSpeciesごとに集計する
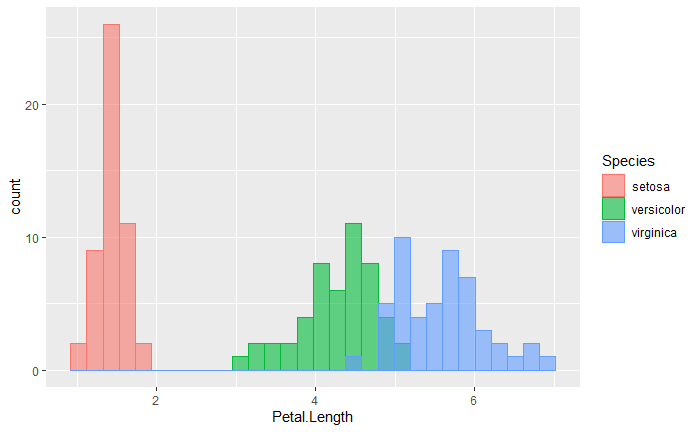
fillやcolorをSpecies列として指定して、position = "identity"とすることで、Speciesごとにカウントしてそれぞれのヒストグラムを重ね合わせて作図することができます。
種ごとに色を塗り分けると、それぞれの種ではピークが1つのきれいな分布になっていたことがわかります。
fillやcolorを塗り分けたい項目に設定すると塗分けた項目ごとの分布が可視化できる。
この時「position = "identity"」を指定しないと種ごとに集計せずに、全部の種のデータをまとめて集計した結果をプロットしてしまうため注意が必要です。
階級の幅を変える
ヒストグラムで集計する階級の幅を変える方法を紹介します。分布の特徴をつかむのに適切な幅で作図することは大事です。
今回は先ほどの色を塗り分けた図の幅を少し広くして作図する場合のコードを紹介します。
library(ggplot2) ggplot(data = iris, aes(x = Petal.Length, fill = Species, color = Species)) + geom_histogram(position = "identity", alpha = .6, binwidth = 0.4) # binwidthを少し大きく変更する
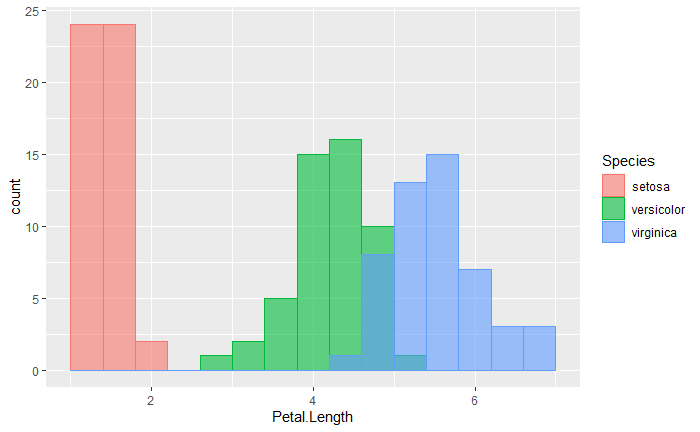
幅を変えるときは「binwidth」や「bins」に数値を指定して幅を変更します。
binwidthは棒1本あたりの幅を指定できます。1にすると1刻みでデータを集計します。
また、binsは棒の数を指定できます。最小値から最大値までの値の幅を何個に分割にするかを指定できます。
ヒストグラムで集計する幅を変える時は binwidth や bins 引数を設定。
上下逆向きで重ねる
2つのヒストグラムを比較するときに便利な上下逆向きで重ねる方法を紹介します。
先に紹介した色を塗り分けて重ねる方法でも比較できますが、2つのヒストグラムを比較する時はこちらの方がお勧めです。
今回はSpeciesが「Versicolor」と「Virginica」のものだけを使って(Setosaは除いて)、それぞれを別々に集計して上下逆向きで重ねる場合のコードを紹介します。
library(tidyverse) # パイプ演算子も使いたいのでtidyerseを呼び出す
# 種ごとにベクトルとして作成
versicolor = iris3[ , "Petal L.", "Versicolor"]
virginica = iris3[ , "Petal L.", "Virginica"]
# ここからが作図
data.frame(versicolor, virginica) %>% # 作成したベクトルを列に持つデータフレームを作成
ggplot() + # 作成したデータを使って作図を開始
geom_histogram(aes(x = versicolor, y = ..count..), # versicolor列をy軸の正の方向にプロット
fill = "#8E97FA", color = "black", # 塗りつぶしや枠線の色を直接指定
binwidth = 0.2) + # 階級幅を0.2に指定
geom_histogram(aes(x = virginica, y = -..count..), # versicolor列をy軸の負の方向にプロット
fill = "#F59393", color = "black",
binwidth = 0.2) +
geom_label(aes(x = 6.5, y = 7, label = "versicolor"), # データの情報を直接記載するために、文字を書き込む内容と位置を指定
color = "#8E97FA") + # 直観的に理解しやすいようにラベルの色と棒の塗りつぶしの色が同じになるように指定
geom_label(aes(x = 6.5, y = -7, label = "virginica"), # 今度はvirginicaのラベルを追加
color = "#F59393") +
labs(x = "Petal L.") # x軸のラベルを本来の値の意味である「Petal L.」に設定する
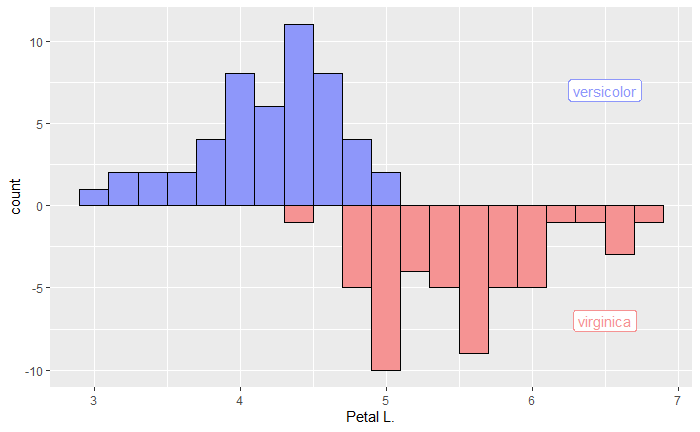
今回のコードはかなり長いものになってしまいましたが、大事なポイントは geom_histogram()関数を2回宣言し、それぞれで異なる列をy軸の正の方向と負の方向でそれぞれ分けて作図している点です。
コードの動き方がイメージしずらい方は上のコードを部分的に削除したり、パラメータを変更したりして図がどのように変化するか確認してみましょう。正直言ってgeom_label()のところはなくても大丈夫です。
ヒストグラムの使いどころ
今回紹介したヒストグラムですが、データの分布を簡単に確認する時に重宝する可視化法の1つです。解析を始める前にデータの特徴をつかむためにプロットしてみると良いかもしれません。
正規分布しているのか、ピークが複数あって何か影響を及ぼしている共変量がありそうなのかなどを確認してから解析した方が、データから有用な情報を引き出すことができるようになります。
データの分布を確認するときはとりあえずヒストグラムを使うと良い。